해당 포스팅은 사내 k8s 클러스터에 EFK 로깅시스템을 구축한 기록으로
기본적으로 k8s 클러스터가 구축되어 있고 kubectl 연결이 되어 있다는 가정하에 작성되었습니다.
1. 구축 방법에 대한 고민
나만 구축하고 끝날게 아니라 클라우드 환경에 누구나 쉽게 구축이 가능해야 하기 때문에
적극적으로 관리되는 Helm Chart 를 활용하는게 좋겠다고 생각했습니다.
하지만 후보군으로 뒀던 Chart들이 모두 문제가 있어
결국 이곳을 참고해서 yaml 파일을 직접 작성해서 구성하는 방법으로 진행했습니다.
후보군으로 뒀던 Helm Chart 들은 아래와 같습니다.
1. https://github.com/komljen/helm-charts/tree/master/efk
github 외에 개인블로그도 운영중인 사람으로 해당 블로그를 보고 따라하면
정말 간단하게 EFK 스택을 구성할 수 있습니다. 실제 인프런 강의에서도 이를 활용하고 있습니다.
Operator, Curator 등 부족한 게 없는데 문제는 Elastic 7.* 버전 이상은 지원하지 않으며
무엇보다 소스 공개가 제대로 되어 있지 않아 이슈를 분석하거나 커스텀해서 사용하기가 힘듭니다.
2. https://github.com/helm/charts/tree/master/stable/elasticsearch
Elastic 6.* 버전까지는 안정화 되었지만 현재 Deprecated 된 상태이고
역시 Elastic 7.* 버전 이상은 지원하지 않습니다.
3. https://github.com/elastic/helm-charts
현재 가장 적극적으로 유지되고 있는 Helm Chart elastic 7.10버전까지 테스트가 완료되었다고 합니다.
가능하다면 이것을 활용하는 것이 가장 좋아보입니다.
하지만 실제 install 을 하면 계속 아래 에러로 실패해서 해결방법을 찾지 못하고 포기했습니다.
설치 방법은 위 github에 나와 있기 때문에 혹시 helm install 에 성공하시면 공유 좀 부탁드립니다
|
master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster, and this node must discover master-eligible nodes |
2. EFK Stack?
Elasticsearch, Fluent-bit, Kibana 의 조합으로 로그를 수집, 관리, 탐색 하는 시스템을 의미합니다.
일반적으로 F 는 Fluentd 를 의미 하는데 좀 더 경량화 된 Fluent-bit 가 등장함에 따라
이것만으로 충분한 경우 최근에는 Fluent-bit 가 많이 사용되고 있습니다.
둘의 차이는 공식 홈페이지 에서 확인 가능한데
플러그인의 차이로 굳이 많은 플러그인이 필요없다면 Fluent-bit 를 선택하지 않을 이유가 없습니다.
Logstash?
추가로 과거 ELK Stack 이란 이름으로 Fluentd 대신 Logstash 가 사용되었는데
이 둘의 차이는 이곳 에 잘 정리가 되어 있습니다.
그대로 인용해서 요약하면 아래와 같습니다. (단순한게 최고입니다)
LogStash는 20개의 Fixed-Size Event를 제한된 On-Memory queue에 담기 때문에,
재시작시 지속성을 위해 External queue의 의존도를 높힌다.
이는 LogStash의 잘 알려진 문제로 Redis나 Kafka를 버퍼로 사용함으로서 문제를 해결할 수 있다.
단점에 대한 해결-접근성은 좋은편이지만, 안정성을 위해 독립적으로 동작시키기 어렵다는건 분명한 단점이다.
Fluentd는 in-memory 또는 디스크를 활용함할 수 있는 고도화된 버퍼링 시스템을 지원한다.
물론, 매개변수를 별도로 구성해야 한다는 단점이 있지만, 2개의 미들웨어를 이해해야하는 LogStash 보단 낫다.
LogStash 는 ElasticSearch 와 너무 가까이 있다보니, ‘이정도면 충분한데’ 라는 느끼이 적잖다.
반면 Fluentd 는 ‘이거 혼자만으로도 가능한데?’ 가 조금 강하다.
모든 경우에 환경을 갖추고 진행하는게 아니다보니, Fluentd 로의 이동은 너무 자연스러운것 일지도..
Elastic 라이센스 정책
Elasitc 한국 직원이 정리한 라이센스 정책을 이곳에서 확인할 수 있는데
역시 그대로 인용해서 요약하면 핵심은 아래와 같습니다.
Elastic 제품을 내재 한 제품으로 비즈니스를 하려면
Elastic사와 협약을 체결하지 않은 경우 OSS 버전으로만 비즈니스를 해야 합니다.
SI, 클라우드 서비스, 컨설팅, 기술지원, 교육 등이 모두 포함됩니다.
그래서 클라우드 서비스 사업자들 중에 Elastic 사와 파트너 협약을 하지 않고
Elastic Stack 서비스를 제공하는 사업자들은 OSS 라이센스에 속한 기능만 서비스를 해야 합니다.
회사에서 APM, 로깅, 메트릭 등이 필요하면, Elastic 의 Basic 기능에서 제공되니 가져다 쓰시면 됩니다.
하지만 Elastic 에서 어떤 회사, 조직, 개인의 Basic 라이센스 기능의 사용이
Elastic 비즈니스에 부정적인 영향을 미친다고 판단이 되는 경우에는 어떤 조치를 취할 수도 있지 않을까 생각 해 봅니다.
2020년 1월 k8s 전용 Elastic Stack인 ECK(Elastic Cloud On Kubernetes) 가 정식 출시 되었고
공식 홈페이지 메뉴얼에 따라 매우 간단하게 구성이 가능합니다.
하지만 Basic, Enterprise 버전만 제공되고 Basic 버전은 무료 사용가능하다고 하지만
위와 같은 라이센스 정책 때문에 결국 사용을 할수가 없습니다.
3. 컨테이너 로그는 어디에 쌓이나?
컨테이너 로그도 기본적으로 파일로 생성됩니다.
k8s가 아닌 기존 환경에서는 이를 위해 어플리케이션 단에서 Logger를 통해
콘솔출력과 함께 파일출력도 함께 설정해줘야 했지만 k8s 환경이라면
어플리케이션 에서는 단순히 콘솔출력만 진행하고 이후 로그파일 관리는 컨테이너 런타임이 수행합니다.
대표적으로 사용되는 컨테이너 런타임인 Docker 에서는
기본적으로 노드별로 아래 경로에 로그파일을 생성해서 관리합니다.
(Logrotate 설정도 기본적으로 Docker 런타임에서 옵션으로 제공 됩니다)
|
/var/lib/docker/containers/컨테이너_id/컨테이너_id-json.log |
kubelet은 이 파일에 대해 아래와 같은 심볼릭 링크를 생성합니다.
|
/var/log/containers/파드이름_파드네임스페이스이름_컨테이너이름컨테이너ID.log /var/log/pods/파드UID/컨테이너이름/0.log |
사실 로그는 이렇게 파일로 관리하는 것 만으로도 충분할 수도 있습니다.
tail 로 모니터링 해도 되고 직접 파일을 열어서 키워드 검색을 통해 찾아봐도 됩니다.
그런데 아래와 같은 문제로 인해 기존환경보다 보다 더 필수적으로 Logging 시스템이 필요합니다.
1. k8s 환경에서는 로그파일이 Docker 런타임에 의해 컨테이너 단위로 관리됩니다.
컨테이너가 재구동되면 기존 컨테이너가 삭제되고 새로운 컨테이너가 생성되는데
이때 기존 로그파일도 삭제됩니다.
2. 노드가 여러개일 경우(대부분이 이럴듯) 일반적인 상황에서는
어떤 노드에 컨테이너가 띄워질지 알 수 없기 때문에 모든 노드를 다 찾아봐야 합니다.
3. replicas 가 여러개일 경우 당연히 컨테이너도 여러개가 되고
역시 해당 컨테이너 로그파일을 모두 찾아봐야 합니다.
kubelet 이 로그파일에 대해 별도의 심볼릭링크를 생성하는 이유는
아마도 컨테이너 런타임이 꼭 Docker가 아닐 수 있기 때문인듯 한데
같은 이유로 Fluent-bit에서는 원본파일이 아닌 심볼릭링크를 tailing 해서 로그를 수집하면 되고
구성은 대략 아래와 같게 됩니다.

4. Elasticsearch 구축
Elasticsearch 는 기본적으로 하나 이상의 노드가 클러스터 형태로 구성됩니다.
k8s 기준으로 보면 Elasticsearch 에 관여하는 Pod들이 여러개라고 생각하면 되고
이는 Controller 에서 replicas 로 정의합니다.
Elastic 에서는 공식 홈페이지에서 Elasticsearch Docker 이미지가 제공되고
Elasticsearch 구축 yaml 파일 전문은 아래와 같습니다.
elasticsearch.yaml
|
kind: Service apiVersion: v1 metadata: name: elasticsearch-svc labels: app: elasticsearch spec: clusterIP: None ports: - name: rest port: 9200 - name: nodecom port: 9300 selector: app: elasticsearch --- kind: Service apiVersion: v1 metadata: name: elasticsearch-svc-nodeport labels: app: elasticsearch spec: type: NodePort ports: - nodePort: 30920 port: 9200 targetPort: 9200 protocol: TCP selector: app: elasticsearch --- apiVersion: apps/v1 kind: StatefulSet metadata: name: elasticsearch-node labels: app: elasticsearch spec: serviceName: elasticsearch-svc replicas: 5 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.9.3 imagePullPolicy: IfNotPresent resources: limits: cpu: 1000m memory: 2Gi requests: cpu: 500m memory: 1Gi ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP env: - name: cluster.name value: elasticsearch-cluster - name: node.name valueFrom: fieldRef: fieldPath: metadata.name - name: discovery.seed_hosts value: "elasticsearch-svc" - name: cluster.initial_master_nodes value: "elasticsearch-node-0,\ elasticsearch-node-1,\ elasticsearch-node-2" - name: ES_JAVA_OPTS value: "-Xms1024m -Xmx1024m" initContainers: - name: fix-permissions image: busybox:1.32.0-musl imagePullPolicy: IfNotPresent command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: privileged: true volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox:1.32.0-musl imagePullPolicy: IfNotPresent command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit image: busybox:1.32.0-musl imagePullPolicy: IfNotPresent command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true volumeClaimTemplates: - metadata: name: data spec: accessModes: [ "ReadWriteOnce" ] resources: requests: storage: 10Gi |
discovery.seed_hosts 클러스터에 참여하는 컨테이너 호스트 정보를 제공하기 위해
Headless Service 가 필요합니다.
Headless Service 가 아니어도 상관은 없지만 그 경우
replicas로 생성되는 각 컨테이너의 내부 도메인 주소를 일일히 명시해야 합니다.
Headless Service 라면 위와같이 Service 만 명시하는 것만으로 충분합니다.
외부 클러스터(실제 서비스)에 있는 Fluent-bit가 접근해야 하기 때문에
NodePort Service 도 필요합니다.
클러스터에 참여하는 컨테이너 중 마스터노드를 cluster.initial_master_nodes 와 같이
특정하기 위해 컨테이너의 이름이 고정적이고 예측이 가능해야합니다.
이에 Pod 배포에는 StatefulSet 이 사용되어야 합니다.
Elasticsearch 에서는 안정적인 서비스를 위해 마스터노드와 데이터노드를 구분하고
마스터 노드는 최소 3개이상 홀수로 두는 것을 권장하고 있습니다.
여기에서는 discovery.seed_hosts 에 의해 총 5개의 노드가 클러스터로 구성되고
cluster.initial_master_nodes 로 지정된 3개 노드가 마스터노드 후보로 등록되며
Elasticsearch 에서는 그 중 1개를 마스터 노드로 선출합니다.
Elasticsearch 7.* 버전 기준 초기 힙사이즈는 기본적으로 1g로 설정되어 있는데
위와 같이 ES_JAVA_OPTS 를 통해 변경할 수 있습니다.
다만 최소힙사이즈와 최대힙사이즈는 반드시 동일한 값으로 지정해야 합니다.
그렇지 않으면 구성시 부트스트랩 검사가 실패합니다.
initContainers 를 통해 Elasticsearch 가 구성되는 WorkerNode의 설정을 변경합니다.
increase-vm-max-map, increase-fd-ulimit 설정은 Elastic 공식홈페이지 지시를 따릅니다.
아래 명령어로 클러스터에 Elasticsearch 를 구축합니다.
|
kubectl apply -f elasticsearch.yaml |
잠시후 아래 명령어로 pod이 제대로 생성된 것을 확인합니다.
|
kubectl get pod |

WorkerNode 중 하나를 선택해서 nodePort 로 정상 접근되는 것을 확인합니다.
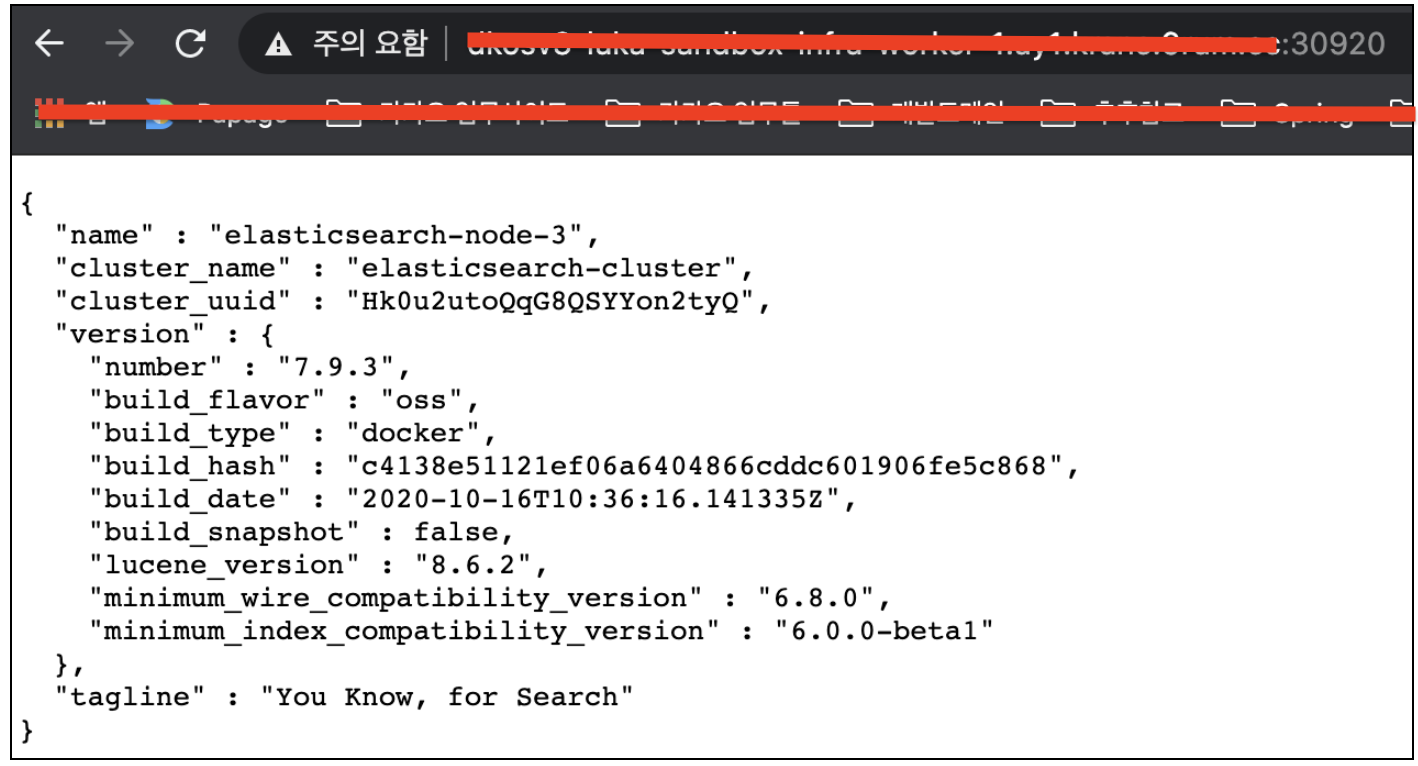
5. Fluent-bit 구축
로그를 수집하고자 하는 서비스 클러스터에 Fluent-bit를 구축합니다.
기본적으로 서비스 Pod 과 분리하기 위해 logging 이라는 별도의 namespace 를 생성해서 관리합니다.
이를 위해 namespace 를 먼저 생성합니다.
|
kubectl create namespace logging |
Fluent-bit 구축을 위한 yaml 파일 전문은 아래와 같습니다.
fluent-bit.yaml
|
apiVersion: v1 kind: ServiceAccount metadata: name: fluent-bit-sa namespace: logging labels: app: fluent-bit-logging --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluent-bit-cr namespace: logging labels: app: fluent-bit-logging rules: - apiGroups: [""] resources: - pods - namespaces verbs: ["get", "list", "watch"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluent-bit-crb namespace: logging labels: app: fluent-bit-logging roleRef: kind: ClusterRole name: fluent-bit-cr apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: fluent-bit-sa namespace: logging --- apiVersion: v1 kind: ConfigMap metadata: name: fluent-bit-config namespace: logging labels: app: fluent-bit-logging data: # Configuration files: server, input, filters and output # ====================================================== fluent-bit.conf: | [SERVICE] Flush 1 Log_Level info Daemon off Parsers_File parsers.conf HTTP_Server On HTTP_Listen 0.0.0.0 HTTP_Port 2020
@INCLUDE input-kubernetes.conf @INCLUDE filter-kubernetes.conf @INCLUDE output-elasticsearch.conf
input-kubernetes.conf: | [INPUT] Name tail Tag kube.* Path /var/log/containers/*.log Parser docker DB /var/log/flb_kube.db Mem_Buf_Limit 5MB Skip_Long_Lines On Refresh_Interval 10
filter-kubernetes.conf: | [FILTER] Name kubernetes Match kube.* Kube_URL https://kubernetes.default.svc:443 Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token Kube_Tag_Prefix kube.var.log.containers. Merge_Log On Merge_Log_Key log_processed K8S-Logging.Parser On K8S-Logging.Exclude Off
output-elasticsearch.conf: | [OUTPUT] Name es Match * Host ${FLUENT_ELASTICSEARCH_HOST} Port ${FLUENT_ELASTICSEARCH_PORT} Logstash_Format On Logstash_Prefix melon-trackzero Replace_Dots On Retry_Limit False tls Off tls.verify Off
parsers.conf: | [PARSER] Name docker Format json Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluent-bit-ds namespace: logging labels: app: fluent-bit-logging spec: selector: matchLabels: app: fluent-bit-logging updateStrategy: type: RollingUpdate template: metadata: labels: app: fluent-bit-logging spec: containers: - name: fluent-bit image: fluent/fluent-bit:1.6.8 imagePullPolicy: IfNotPresent ports: - containerPort: 2020 env: - name: FLUENT_ELASTICSEARCH_HOST value: "es-node.test.com" - name: FLUENT_ELASTICSEARCH_PORT value: "30920" volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: fluent-bit-config mountPath: /fluent-bit/etc/ terminationGracePeriodSeconds: 10 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: fluent-bit-config configMap: name: fluent-bit-config serviceAccountName: fluent-bit-sa tolerations: - key: node-role.kubernetes.io/master operator: "Exists" effect: "NoSchedule" |
위에서 설명했듯이 컨티이너 로그파일은 노드별로 생성되기 때문에
기본적으로 모든 노드에 Fluent-bit Pod이 떠 있어야 합니다.
이를 위해 Pod 배포에는 DaemonSet 이 사용됩니다.
Fluent-bit 이미지는 Fluent 에서 공식적으로 제공되는 이미지를 사용하며
해당 이미지에서 ClusterRole 권한을 필요로 하기 때문에
위와 같이 ServiceAccount 를 별도로 생성해서 ClusterRole을 Binding 해서 사용합니다.
수집한 로그를 보내줄 Elasticsearch 도메인은
FLUENT_ELASTICSEARCH_HOST, FLUENT_ELASTICSEARCH_PORT 에
위에서 Elasticsearch 구축시 정의한 NodePort 정보를 명시하도록 합니다.
Fluent-bit Pod을 띄우는 방법은 굉장히 단순합니다.
필요한 config를 참조해서 프로세스가 실행되는 것인데
ConfigMap으로 Fluent-bit 에서 사용할 config 파일 내용을 정의하고
실제 컨테이너에서 볼륨 연결을 통해 config 파일로 사용합니다.
공식홈페이지에 나와있는 Fluent-bit 데이터 흐름에 대한 파이프라인은 아래와 같습니다.
각 파이프라인에는 다양한 플러그인이 제공되는데 config 파일에 사용할 플러그인을 정의하면 됩니다.
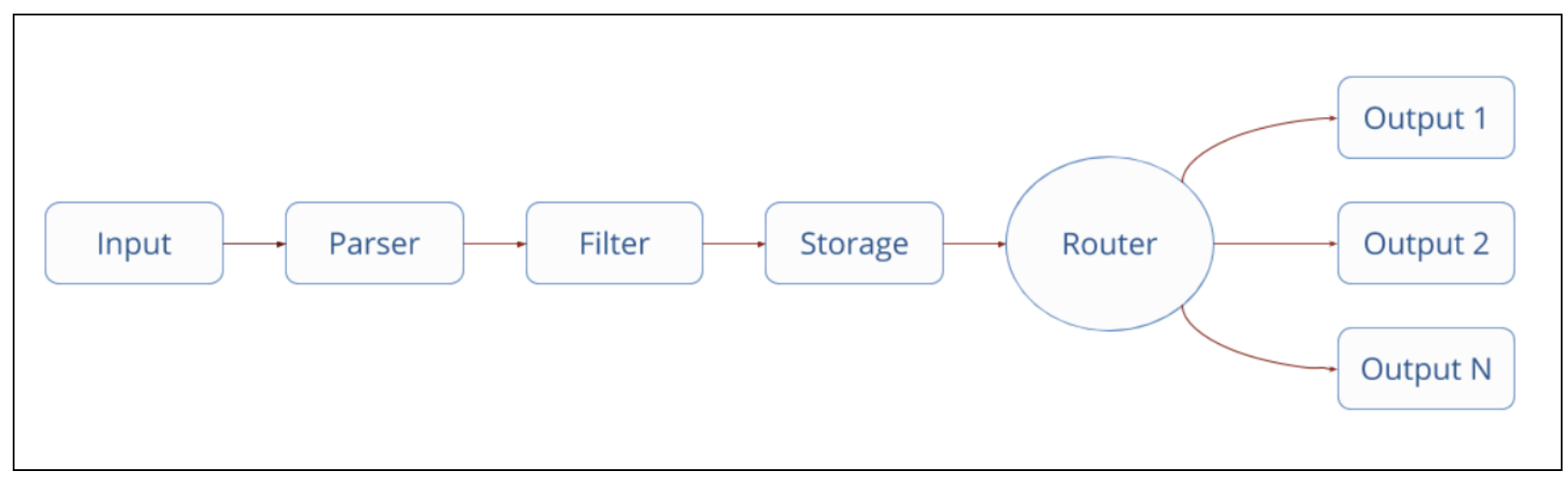
여기에서는 ConfigMap 을 통해 정의한 플러그인에 의해 아래와 같이 동작하게 됩니다.
Input 파이프라인에서 Tail 플러그인을 통해 파일을 tailing 해서 로그를 수집합니다.
Parser 파이프라인에서 Json Parser를 지정해서 Docker 로그 구문을 분석합니다.
Filter 파이프라인에서 Kubernetes 플러그인을 통해 아래 정보를 추가로 수집합니다.
-> Pod이름/ID, namespace, Container이름/ID, Label, annotations
Output 파이프라인에서 Elasticsearch 플러그인을 통해 수집한 로그를 Elasticsearch 로 보냅니다.
-> Logstash_Prefix 에는 서비스별로 적절한 값을 할당합니다.
아래 명령어로 Fluent-bit 를 구축합니다.
|
kubectl apply -f fluent-bit.yaml |
logging namespace 에 클러스터의 노드 갯수만큼 Pod이 생성된 것을 확인합니다.
|
kubectl get pod -n logging |

6. Kibana 구축
Elasticsearch 를 구축했던 클러스터로 돌아와서 Kibana 를 구축합니다.
특별한 것은 없고 클러스터에 Ingress 를 추가하고 도메인을 생성해서 연결했습니다.
주의할 점은 Kibana Image 버전은 Elasticsearch Image 버전과 반드시 일치해야 합니다.
kibana.yaml
|
apiVersion: apps/v1 kind: Deployment metadata: name: kibana labels: app: kibana spec: replicas: 1 selector: matchLabels: app: kibana template: metadata: labels: app: kibana spec: containers: - name: kibana image: docker.elastic.co/kibana/kibana-oss:7.9.3 imagePullPolicy: IfNotPresent resources: limits: cpu: 1000m memory: 1Gi requests: cpu: 700m memory: 1Gi env: - name: ELASTICSEARCH_HOSTS value: http://elasticsearch-svc:9200 ports: - containerPort: 5601 --- apiVersion: v1 kind: Service metadata: name: kibana-svc labels: app: kibana spec: ports: - port: 80 targetPort: 5601 protocol: TCP selector: app: kibana --- apiVersion: extensions/v1beta1 kind: Ingress metadata: name: kibana-ing labels: app: kibana annotations: nginx.ingress.kubernetes.io/rewrite-target: / spec: rules: - host: kibana.test.com http: paths: - path: / backend: serviceName: kibana-svc servicePort: 80 |
지정한 도메인으로 kibana에 정상 접속되는 것을 확인합니다.
Elasticsearch 에 수집된 데이터로 생성된 인덱스로 인덱스패턴을 생성합니다.

Kibana 에서 조회조건으로 사용할 시간값과 매칭할 데이터를 선택합니다.
@timestamp 는 Fluent-bit 에서 Json Parser 에 의해 로그데이터의 시간값이 할당됩니다.
로그 데이터를 검색해봅니다.

7. Curator 를 통한 Elasticsearch 인덱스 관리
지속적인 로그수집을 통해 Elasticsearch 인덱스가 생성되다보면 디스크 용량이 부족할 수 밖에 없습니다.
이에 주기적으로 인덱스를 삭제해줄 필요가 있는데 Elastic 에서 제공하는 자동화도구인 Curator를 활용하면 됩니다.
직접 설치해서 cli 명령을 cronTab으로 등록해도 될 것 같지만
Docker Hub에 공개된 Curator 이미지와 k8s CronJob 을 활용하도록 합니다.
curator.yaml
|
apiVersion: v1 kind: ConfigMap metadata: name: curator-config labels: app: curator data: action_file.yml: |- --- # Remember, leave a key empty if there is no value. None will be a string, # not a Python "NoneType" # # Also remember that all examples have 'disable_action' set to True. If you # want to use this action as a template, be sure to set this to False after # copying it. actions: 1: action: delete_indices description: "Clean up ES by deleting old indices" options: timeout_override: continue_if_exception: False disable_action: False ignore_empty_list: True filters: - filtertype: age source: name direction: older timestring: '%Y.%m.%d' unit: days unit_count: 7 field: stats_result: epoch: exclude: False config.yml: |- --- # Remember, leave a key empty if there is no value. None will be a string, # not a Python "NoneType" client: hosts: elasticsearch-svc port: 9200 url_prefix: use_ssl: certificate: client_cert: client_key: ssl_no_validate: True http_auth: timeout: 7 master_only: False logging: loglevel: INFO logfile: logformat: default blacklist: ['elasticsearch', 'urllib3'] --- apiVersion: batch/v1beta1 kind: CronJob metadata: name: curator-cj labels: app: curator spec: schedule: "0 1 * * *" successfulJobsHistoryLimit: 1 failedJobsHistoryLimit: 3 concurrencyPolicy: Forbid startingDeadlineSeconds: 120 jobTemplate: spec: template: spec: containers: - image: bobrik/curator imagePullPolicy: IfNotPresent name: curator args: ["--config", "/etc/config/config.yml", "/etc/config/action_file.yml"] volumeMounts: - name: config mountPath: /etc/config volumes: - name: config configMap: name: curator-config restartPolicy: OnFailure |
위와 같이하면 매일 01시에 최근 7일 이후 인덱스가 삭제됩니다.
아래 명령어로 Elasticsearch 가 설치된 클러스터에 ConfigMap과 CronJob을 등록합니다.
|
kubectl apply -f curator.yaml |
'Base > Logging' 카테고리의 다른 글
| Kibana 사용법 간단 정리 (0) | 2021.08.25 |
|---|